 Kafka入门
Kafka入门
# docker中启动kafka
默认启动zookeeper
docker run -d --name kafka --publish 9092:9092 --link zookeeper --env KAFKA_ZOOKEEPER_CONNECT=zookeeper:2181 --env KAFKA_ADVERTISED_HOST_NAME=192.168.30.131 --env KAFKA_ADVERTISED_PORT=9092 --volume /etc/localtime:/etc/localtime wurstmeister/kafka:latest
# 创建topic
[root@nrStudy ~]# docker exec kafka \
> kafka-topics.sh \
> --create --topic hello \
> --partitions 1 \
> --zookeeper zookeeper:2181 \
> --replication-factor 1
Created topic hello.
2
3
4
5
6
7
查看topic
[root@nrStudy ~]# docker exec kafka kafka-topics.sh --list --zookeeper zookeeper:2181 hello
hello
2
# 发送消息
docker exec kafka kafka-console-producer.sh --broker-list localhost:9092 --topic hello
# 监听消息
docker exec kafka kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic hello --from-beginning
# SpringBoot整合
项目地址:https://github.com/hedsay/Kafka_learning
# 生产者
@Component
public class KafkaProducer {
private Logger logger = LoggerFactory.getLogger(KafkaProducer.class);
@Resource
private KafkaTemplate<String, Object> kafkaTemplate;
public static final String TOPIC_TEST = "hello";
public static final String TOPIC_GROUP = "test-consumer-group";
public void send(Object obj) {
String obj2String = JSON.toJSONString(obj);
logger.info("准备发送消息为:{}", obj2String);
// 发送消息
ListenableFuture<SendResult<String, Object>> future = kafkaTemplate.send(TOPIC_TEST, obj);
future.addCallback(new ListenableFutureCallback<SendResult<String, Object>>() {
@Override
public void onFailure(Throwable throwable) {
//发送失败的处理
logger.info(TOPIC_TEST + " - 生产者 发送消息失败:" + throwable.getMessage());
}
@Override
public void onSuccess(SendResult<String, Object> stringObjectSendResult) {
//成功的处理
logger.info(TOPIC_TEST + " - 生产者 发送消息成功:" + stringObjectSendResult.toString());
}
});
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
# 消费者
一个消费者能消费多个partition;
消费者组中消费者数量不能比一个topic中的partition数量多,否则多出来的消费者消费不到消息;

设置消费者组,消费指定topic:
@Component
public class KafkaConsumer {
private Logger logger = LoggerFactory.getLogger(KafkaConsumer.class);
@KafkaListener(topics = KafkaProducer.TOPIC_TEST, groupId = KafkaProducer.TOPIC_GROUP)
public void topicTest(ConsumerRecord<?, ?> record, Acknowledgment ack, @Header(KafkaHeaders.RECEIVED_TOPIC) String topic) {
Optional<?> message = Optional.ofNullable(record.value());
if (message.isPresent()) {
Object msg = message.get();
logger.info("topic_test 消费了: Topic:" + topic + ",Message:" + msg);
ack.acknowledge();// 手动提交offset
}
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
设置消费者组,多topic,指定分区,指定偏移量消费 及 设置消费者个数;
@KafkaListener(groupId = "testGroup", topicPartitions = {
@TopicPartition(topic = "topic1", partitions = {"0", "1"}),
@TopicPartition(topic = "topic2", partitions = "0",partitionOffsets = @PartitionOffset(partition = "1",initialOffset = "100"))}
,concurrency = "3")//concurrency就是同组下的消费者个数,就是并发消费数,建议小于等于分区总数
public void listenGroup(ConsumerRecord<String, String> record,Acknowledgment ack) {
String value = record.value();
System.out.println(value);
System.out.println(record);
//手动提交offset
ack.acknowledge();
}
2
3
4
5
6
7
8
9
10
11
poll过程:
消费者建立与broker之间长连接,开始poll消息;默认一次poll 500条消息,如果两次poll时间超过30s时间间隔,kafka会认为其消费能力过弱,将其踢出消费组。将分区分配给其他消费者。
如果每隔1s内没有poll到任何消息,则继续去poll消息,循环往复,直到poll到消息。如果超出了1s,则此次⻓轮询结束。
kafka会发送 心跳检测,如果超过 10 秒没有收到消费者的心跳,则会把消费者踢出消费组,进行rebalance,把分区分配给其他消费者。
# 测试
@RunWith(SpringRunner.class)
@SpringBootTest
public class KafkaProducerTest {
private Logger logger = LoggerFactory.getLogger(KafkaProducerTest.class);
@Resource
private KafkaProducer kafkaProducer;
@Test
public void test_send() throws InterruptedException {
// 循环发送消息
while (true) {
kafkaProducer.send("hello,Nreal");
Thread.sleep(3500);
}
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
# kafka为什么不支持读写分离?
生产者写入消息、消费者读取消息的操作都是与Leader副本进行交互的,从而实现的是一种主写主读的生产消费模型;
主写从读2个缺点:
数据不一致;
延时问题
Redis主从经历:网络-主节点内存-网络-从节点内存;
Kafka主从经历:网络-主节点内存-主节点磁盘-网络-从节点内存-从节点磁盘;
# 消息回溯
如果消费者组中的某个消费者挂了,挂掉的消费者所消费的分区可能就由存活的消费者消费,存活的消费者需要知道挂掉的消费者消费到哪了;
Kafka用offset表示消费者的消费进度,之前版本这个offset由Zookeeper来管理,但是Zookeeper不适合大量的删改操作,于是把offset在broker以内部topic(_consumer_offsets)方式保存;
消费者消费的时候,都会提交这个offset;
# Zookeeper作用
Broker注册;
Topic注册;
负载均衡;
尽可能将Partition分布到不同的Broker服务器上去;
Kafka 2.8之后,引入了基于Raft协议的KRaft模式,不再依赖Zookeeper;
# 消息队列的持久化
将partition以消息日志的方式存储起来,通过 顺序存储 和 缓存(等到一定时间)才真正把数据写到磁盘,提高速度;
# 消息有序性
- 单个partition的写入是有顺序的,保证全局有序,只能写入一个partition中,如果消费有序,消费者也只能有一个;
- 发送消息时,可以指定topic,partition,key,data 4个参数,同一个key的消息可以保证只发送到一个partition;
# 消息不丢失
Producer重试机制;
send方法是异步的,通过get()方法获取调用结果,如果放松失败就重试;建议写成回调函数形式;
消费者拿到消息后会提交offset;
消费者提交offset后,宕机没有消费成功?
关闭自动提交,每次真正消费完提交offset;但这又出现重复消费问题,消费完还没有提交offset宕机,再消费一次提交offset;消费者需要幂等性处理;
多副本机制;
Kafka为partition引入多副本机制,如果leader副本所在的broker宕机,就要从follower副本中重新选一个leader,但是这个follower副本还没有同步完,造成消息丢失?
设置acks=all,acks是Producer的一个参数;设置为all,表示所有副本全部收到生产者的消息时,生产者才会接收到来自服务器的响应;
或者设置replication.factor>=3,保证每个分区至少3个副本同步完消息;
# 消费失败是否会影响其它消费者?
消费失败的消息会进retry的topic,不影响后面的消息消费;
# 延时队列
在订单创建成功后如果超过 30 分钟没有付款,则需要取消订单,此时可用延时队列来实现;
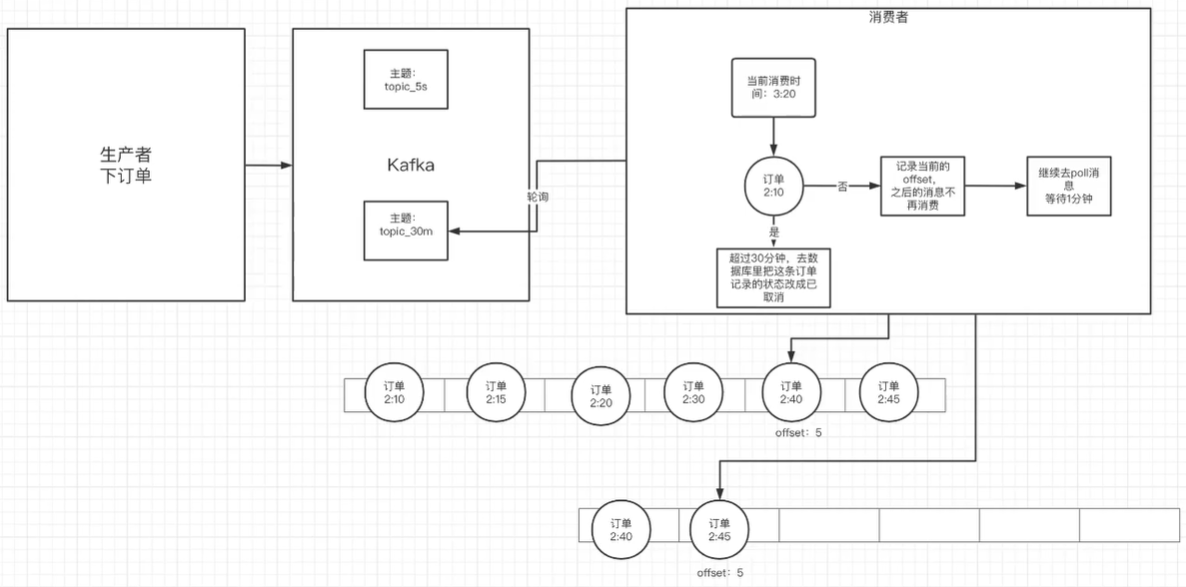
创建多个topic,每个topic表示延时的间隔;
topic_30m: 延时 30 分钟执行的队列
消息发送者发送消息到相应的topic,并带上消息的发送时间;
消费者订阅相应的topic,消费时轮询消费整个topic中的消息;
- 如果消息的发送时间,和消费的当前时间没有超过预设的值,则不消费当前的offset及之后的offset的所有消息都消费;
- 下次继续消费该offset处的消息,判断时间是否已满足预设值;