 IO
IO
# JavaIO
# 三大组件
# Channel&Buffer
channel 有一点类似于 stream,它就是读写数据的双向通道,可以从 channel 将数据读入 buffer,也可以将 buffer 的数据写入 channel,而 stream 要么是输入,要么是输出,channel 比 stream 更为底层;

buffer 则用来缓冲读写数据;
# Selector
多线程监听端口:
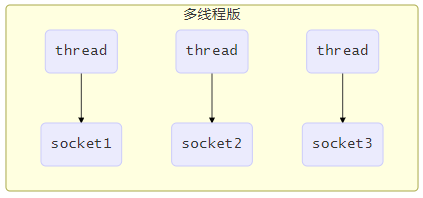
缺点:
- 内存占用高
- 线程上下文切换成本高
- 只适合连接数少的场景
线程池监听端口:

缺点:
- socket工作在阻塞模式下,线程仅能处理一个 socket 连接
- 仅适合短连接场景
selector设计:
selector 的作用就是配合一个线程来管理多个 channel,获取这些 channel 上发生的事件,这些 channel 工作在非阻塞模式下,不会让线程吊死在一个 channel 上。适合连接数特别多,但流量低的场景(low traffic);

调用 selector 的 select() 会阻塞直到 channel 发生了读写就绪事件,这些事件发生,select 方法就会返回这些事件交给 thread 来处理;
# ByteBuffer
非线程安全;
使用 FileChannel 来读取文件内容:
- 向 buffer 写入数据,例如调用 channel.read(buffer)
- 调用 flip() 切换至读模式
- 从 buffer 读取数据,例如调用 buffer.get()
- 调用 clear() 或 compact() 切换至写模式
- 重复 1~4 步骤
@Slf4j
public class Demo {
public static void main(String[] args) {
try (RandomAccessFile file = new RandomAccessFile("helloword/data.txt", "rw")) {
FileChannel channel = file.getChannel();
ByteBuffer buffer = ByteBuffer.allocate(10);
do {
// 向 buffer 写入
int len = channel.read(buffer);
log.debug("读到字节数:{}", len);
if (len == -1) {
break;
}
// 切换 buffer 读模式
buffer.flip();
while(buffer.hasRemaining()) {
log.debug("{}", (char)buffer.get());
}
// 切换 buffer 写模式
buffer.clear();
} while (true);//无循环只能读取一次
} catch (IOException e) {
e.printStackTrace();
}
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
常见方法:
分配空间
Bytebuffer buf = ByteBuffer.allocate(16);1写入数据
调用 channel 的 read 方法
int readBytes = channel.read(buf);1调用 buffer 自己的 put 方法
buf.put((byte)127);1读取数据
调用 channel 的 write 方法
int writeBytes = channel.write(buf);1调用 buffer 自己的 get 方法
byte b = buf.get();1get 方法会让 position 读指针向后走,如果想重复读取数据
- 可以调用 rewind 方法将 position 重新置为 0
- 或者调用 get(int i) 方法获取索引 i 的内容,它不会移动读指针
字符串与ByteBuffer互转
ByteBuffer buffer1 = StandardCharsets.UTF_8.encode("你好"); ByteBuffer buffer2 = Charset.forName("utf-8").encode("你好"); debug(buffer1); debug(buffer2); CharBuffer buffer3 = StandardCharsets.UTF_8.decode(buffer1); System.out.println(buffer3.getClass()); System.out.println(buffer3.toString());1
2
3
4
5
6
7
8
9
# FileChannel
只能工作下阻塞模式下;
获取
不能直接打开 FileChannel,必须通过 FileInputStream、FileOutputStream 或者 RandomAccessFile 来获取 FileChannel,它们都有 getChannel 方法
通过 FileInputStream 获取的 channel 只能读
通过 FileOutputStream 获取的 channel 只能写
通过 RandomAccessFile 是否能读写根据构造 RandomAccessFile 时的读写模式决定
读取
会从 channel 读取数据填充 ByteBuffer,返回值表示读到了多少字节,-1 表示到达了文件的末尾
int readBytes = channel.read(buffer);1写入
SocketChannel
在 while 中调用 channel.write 是因为 write 方法并不能保证一次将 buffer 中的内容全部写入 channel;
ByteBuffer buffer = ...; buffer.put(...); // 存入数据 buffer.flip(); // 切换读模式 while(buffer.hasRemaining()) { channel.write(buffer); }1
2
3
4
5
6
7关闭
channel 必须关闭,不过调用了 FileInputStream、FileOutputStream 或者 RandomAccessFile 的 close 方法会间接地调用 channel 的 close 方法;
位置
获取当前位置
long pos = channel.position();1
2设置当前位置
long newPos = ...; channel.position(newPos);1
2大小
size方法获取文件大小
# Path
jdk7 引入了 Path 和 Paths 类
- Path 用来表示文件路径
- Paths 是工具类,用来获取 Path 实例
Path source = Paths.get("1.txt"); // 相对路径 使用 user.dir 环境变量来定位 1.txt
Path source = Paths.get("d:\\1.txt"); // 绝对路径 代表了 d:\1.txt
Path source = Paths.get("d:/1.txt"); // 绝对路径 同样代表了 d:\1.txt
Path projects = Paths.get("d:\\data", "projects"); // 代表了 d:\data\projects
2
3
4
5
6
7
.代表了当前路径..代表了上一级路径
# Files
检查文件存在:Files.exists
创建一级目录:Files.createDirectory(path)
创建多级目录:Files.createDirectories(path);
遍历目录文件:
public static void main(String[] args) throws IOException {
Path path = Paths.get("path...");
AtomicInteger dirCount = new AtomicInteger();
AtomicInteger fileCount = new AtomicInteger();
Files.walkFileTree(path, new SimpleFileVisitor<Path>(){
@Override
public FileVisitResult preVisitDirectory(Path dir, BasicFileAttributes attrs)
throws IOException {
System.out.println(dir);
dirCount.incrementAndGet();
return super.preVisitDirectory(dir, attrs);
}
@Override
public FileVisitResult visitFile(Path file, BasicFileAttributes attrs)
throws IOException {
System.out.println(file);
fileCount.incrementAndGet();
return super.visitFile(file, attrs);
}
});
System.out.println(dirCount); // 133
System.out.println(fileCount); // 1479
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
匿名内部类和局部变量不在同一个工作空间,不能使用基本类型,基本数据类型保存在栈中,就得使用地址不可变的引用类型,Integer也不行,因为值变了也就意味着对象变了;
# BIO
用户主动调用内核,当前线程被阻塞,用户空间程序等到IO操作彻底完成;
需要创建大量线程,没有请求数据造成线程资源浪费;

服务端:
// 使用 nio 来理解阻塞模式, 单线程
ByteBuffer buffer = ByteBuffer.allocate(16);
ServerSocketChannel ssc = ServerSocketChannel.open();
ssc.bind(new InetSocketAddress(8080));
//连接集合
List<SocketChannel> channels = new ArrayList<>();
while (true) {
//accept 建立与客户端连接, SocketChannel 用来与客户端之间通信
log.debug("connecting...");
SocketChannel sc = ssc.accept(); // 阻塞方法,线程停止运行
log.debug("connected... {}", sc);
channels.add(sc);
for (SocketChannel channel : channels) {
log.debug("before read... {}", channel);
channel.read(buffer); // 阻塞方法,线程停止运行
buffer.flip();
debugRead(buffer);
buffer.clear();
log.debug("after read...{}", channel);
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
客户端:
SocketChannel sc = SocketChannel.open();
sc.connect(new InetSocketAddress("localhost", 8080));
System.out.println("waiting...");
2
3
阻塞模式下,ServerSocketChannel.accept ,SocketChannel.read 没有数据都会使线程暂停,但不会占用cpu;
用多线程的问题:
- 32 位 jvm 一个线程 320k,64 位 jvm 一个线程 1024k,如果连接数过多,必然导致 OOM,并且线程太多,反而会因为频繁上下文切换导致性能降低
- 可以采用线程池技术来减少线程数和线程上下文切换,但治标不治本,如果有很多连接建立,但长时间 inactive,会阻塞线程池中所有线程,因此不适合长连接,只适合短连接
# NIO
当服务器线程发起一个read操作后,不需要等待,而是马上得到一个结果;如果结果是error,就知道数据还没有准备好,再次发送read操作;
一旦内核中数据准备好,并且有受到服务器线程的read请求,就将数据拷贝到用户线程,然后返回;
不断轮询内核数据是否就绪,占用CPU;
服务端:
ByteBuffer buffer = ByteBuffer.allocate(16);
ServerSocketChannel ssc = ServerSocketChannel.open();
ssc.configureBlocking(false); // 非阻塞模式
ssc.bind(new InetSocketAddress(8080));
List<SocketChannel> channels = new ArrayList<>();
while (true) {
//accept 建立与客户端连接, SocketChannel 用来与客户端之间通信
SocketChannel sc = ssc.accept(); // 非阻塞,线程还会继续运行,如果没有连接建立,但sc是null
if (sc != null) {
log.debug("connected... {}", sc);
sc.configureBlocking(false); // 非阻塞模式
channels.add(sc);
}
for (SocketChannel channel : channels) {
//接收客户端发送的数据
int read = channel.read(buffer);// 非阻塞,线程仍然会继续运行,如果没有读到数据,read 返回 0
if (read > 0) {
buffer.flip();
debugRead(buffer);
buffer.clear();
log.debug("after read...{}", channel);
}
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
非阻塞模式,相关方法都不会阻塞,即使没有连接建立,和可读数据,线程仍然在不断运行,白白浪费了 cpu;数据复制过程中,线程实际还是阻塞的;
# IO多路复用
文件描述符FD:关联Linux中的文件
IO多路复用是利用单个线程来同时监听多个FD,并在某个FD可读、可写时得到通知,从而避免无效的等待,充分利用CPU资源。不过监听FD的方式、通知的方式又有多种实现,常见的有:select、poll、epoll;
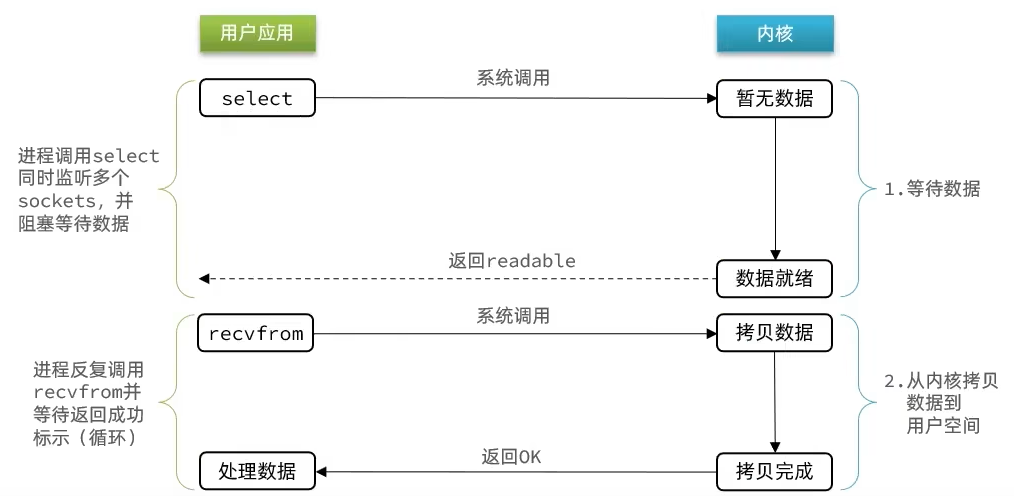
阶段一:
- 用户进程调用select,指定要监听的FD集合
- 内核监听FD对应的多个socket
- 任意一个或多个socket数据就绪则返回readable
- 此过程中用户进程阻塞
阶段二:
- 用户进程找到就绪的socket
- 依次调用recvfrom读取数据
- 内核将数据拷贝到用户空间
- 用户进程处理数据
两阶段都在阻塞
等待顾客要吃什么阻塞,顾客点餐阻塞
# select
把一个文件描述符的数据发给操作系统,让操作系统去遍历,确定哪个文件描述符可以读写,然后告诉用户态去处理;
案例:
比如要监听1,2,5三个数据,此时会执行select函数,然后将整个fd发给内核态,内核态会去遍历用户态传递过来的数据,如果发现这里边都数据都没有就绪,就休眠,直到有数据准备好时,就会被唤醒,唤醒之后,再次遍历一遍,看看谁准备好了,处理掉没有准备好的数据,最后再将这个FD集合写回到用户态中去;但是对于用户态而言,并不知道谁处理好了,所以用户态也需要去进行遍历,然后找到对应准备好数据的节点,再去发起读请求
缺点:频繁的传递fd集合,频繁的去遍历FD等问题
# poll
与select对比:
- select模式中的fd_set大小固定为1024,而pollfd在内核中采用链表,理论上无上限
- 监听FD越多,每次遍历消耗时间也越久,性能反而会下降
# epoll
内核中保存一份文件描述符集合,无需用户态每次重新传入,只需要告诉内核修改部分;
内核不会轮询找到就绪的文件描述符,而是通过异步IO事件唤醒;
内核金辉将带有IO事件的文件描述符传给用户,用户无需遍历整个文件描述符集合;
eventpoll:
- 红黑树-> 记录的事要监听的FD
- 一个是链表->一个链表,记录的是就绪的FD

用户态提供了三个函数:
epoll_create:会在内核创建eventpoll结构体,其里面有一个红黑树,一个链表数据结构的属性;
epoll_ctl:(做的是添加)将要监听的FD添加到红黑树上去,并且给每个fd设置一个监听函数,这个函数会在fd数据就绪时触发,就是准备好了,现在就把fd把数据添加到list_head中去
epoll_wait:(等待fd就绪)在用户态创建一个空的events数组,当就绪之后,回调函数会把数据添加到list_head中去;当调用这个函数的时候,会去检查list_head,有数据就将数据放入到events数组中(写回的都是就绪的fd),并且返回对应的操作的数量,用户态的此时收到响应后,从events中拿到对应准备好的数据的节点,再去调用方法去拿数据
# 事件通知模型
当FD有数据可读时,调用epoll_wait(或者select、poll)可以得到通知。但是事件通知的模式有两种:
LevelTriggered:简称LT,也叫做水平触发。只要某个FD中有数据可读,每次调用epoll_wait都会得到通知。
惊群现象:一个fd准备就绪,所有进程全部唤醒
EdgeTriggered:简称ET,也叫做边沿触发。只有在某个FD有状态变化时,调用epoll_wait才会被通知。
结论:
- ET模式避免了LT模式可能出现的惊群现象
- ET模式结合非阻塞IO读取FD数据,相比LT复杂
# 零拷贝
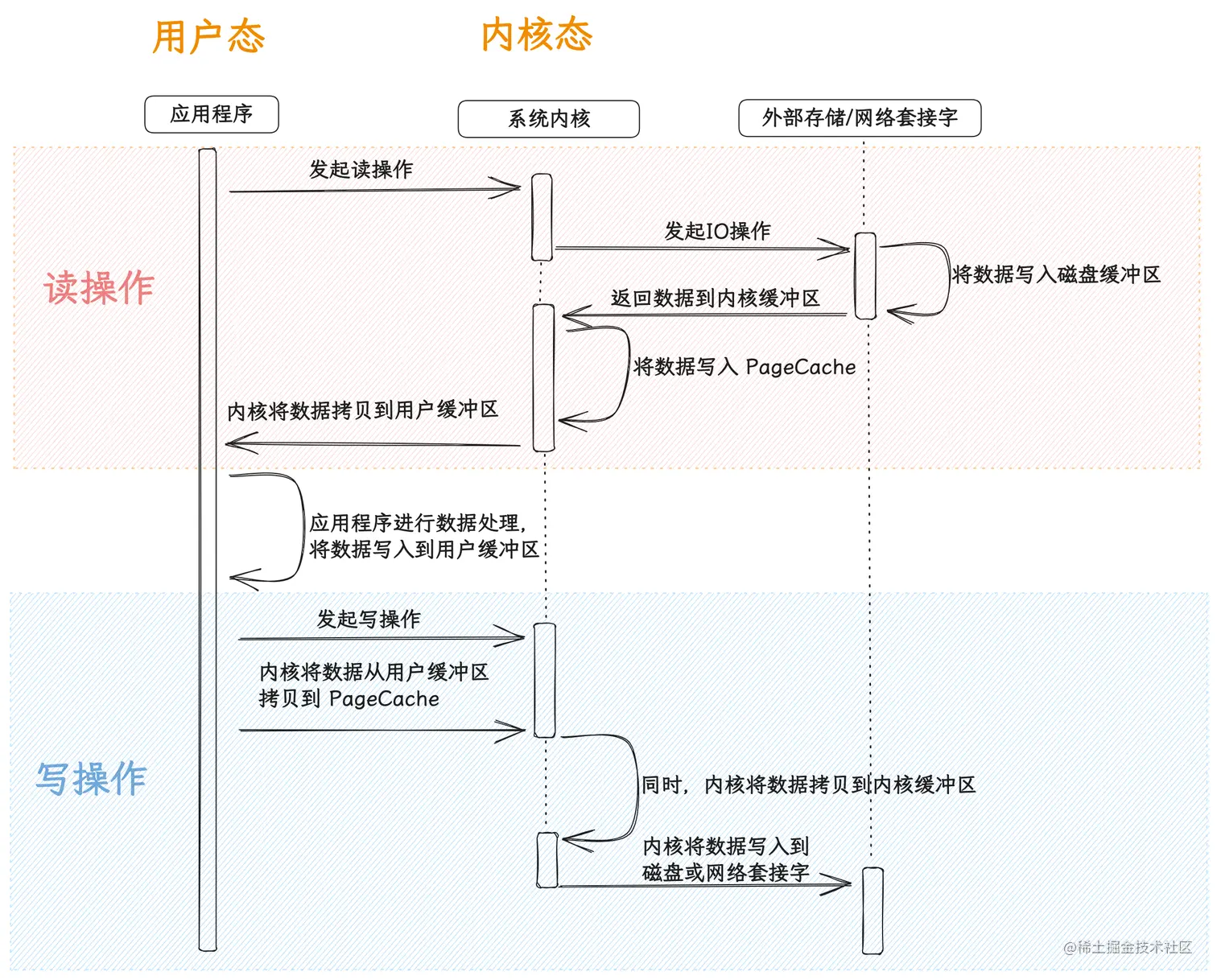
调用read函数:
- DMA把磁盘的拷贝读到内核缓冲区;
- CPU把读内核缓冲区的数据拷贝到用户空间;
调用write函数:
- CPU把用户空间的数据拷贝到Socket内核缓冲区;
- DMA把Socket内核缓冲区的数据拷贝到网卡;
一次读写需要2个DMA拷贝,2次CPU拷贝,DMA拷贝省不了,所谓零拷贝就是把CPU的拷贝省掉;
用户进程直接操作内核,保证内核安全,应用程序调用系统函数时,会发生上下文切换;

IO的瓶颈:数据拷贝,用户态内核态的切换
# DMA
IO控制方式:轮询等待和异步通知两种基本的I/O控制方式。轮询等待方式效率低下,会占用CPU的全部时间,而异步通知方式通过中断控制器来通知CPU,能够有效提高系统的响应速度和效率,然而,中断也存在一个问题,即会打断CPU当前的工作,导致无法同时处理其他任务。
为了解决这个问题:引入了DMA(直接内存访问)控制器。DMA控制器能够让设备在没有CPU参与的情况下,自行将设备的输入/输出数据传输到内存中,从而减少CPU的参与度,提高系统的并发性和响应能力,也避免了数据在用户态和内核态的拷贝(可以直接将数据从内存传输到外设);

# 零拷贝技术实现
减少上下文切换 和 CPU拷贝
# sendfile
将读内核缓冲区的文件描述符/长度信息 发送到Socket内核缓冲区;

- DMA把硬盘数据拷贝至读内核缓冲区;
- CPU把读缓冲区的文件描述符和长度信息发到Socket缓冲区;
- DMA根据文件描述符和数据长度从读内核缓冲区把数据拷贝至网卡;
# mmap
内存映射文件
读缓冲区的地址 和 用户空间的地址 进行映射,实现读内核缓冲区和应用缓冲区共享;
减少一次从读缓冲区到用户缓冲区的CPU拷贝;
select poll epoll都是使用mmap加速内核与用户空间的消息传递;
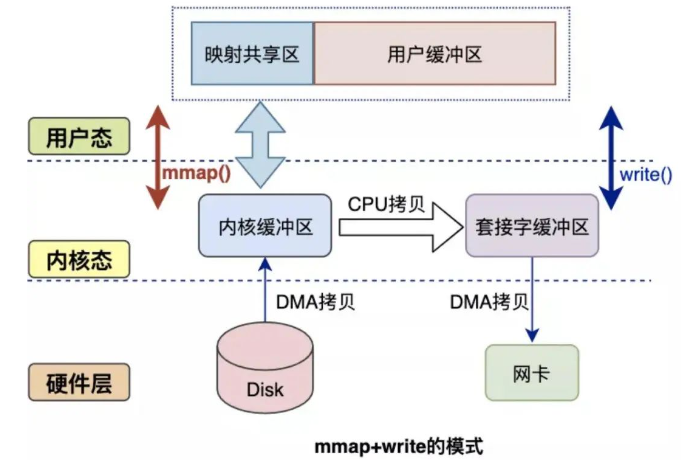
一次读写过程:
- DMA把硬盘数据拷贝到读内核缓冲区;
- CPU读内核缓冲区拷贝至Socket内核缓冲区;
- DMA把Socket内核缓冲区拷贝至网卡;
# java中零拷贝方式
ByteBuffer:可以直接操作字节数据,避免了数据在用户态和内核态之间的复制。
Channel:支持直接将数据从文件通道或网络通道传输到另一个通道,实现文件和网络的零拷贝传输;
# 异步IO
由内核将所有数据处理完成后,由内核将数据写入到用户态中,然后才算完成,所以性能极高,不会有任何阻塞,全部都由内核完成,可以看到,异步IO模型中,用户进程在两个阶段都是非阻塞状态。
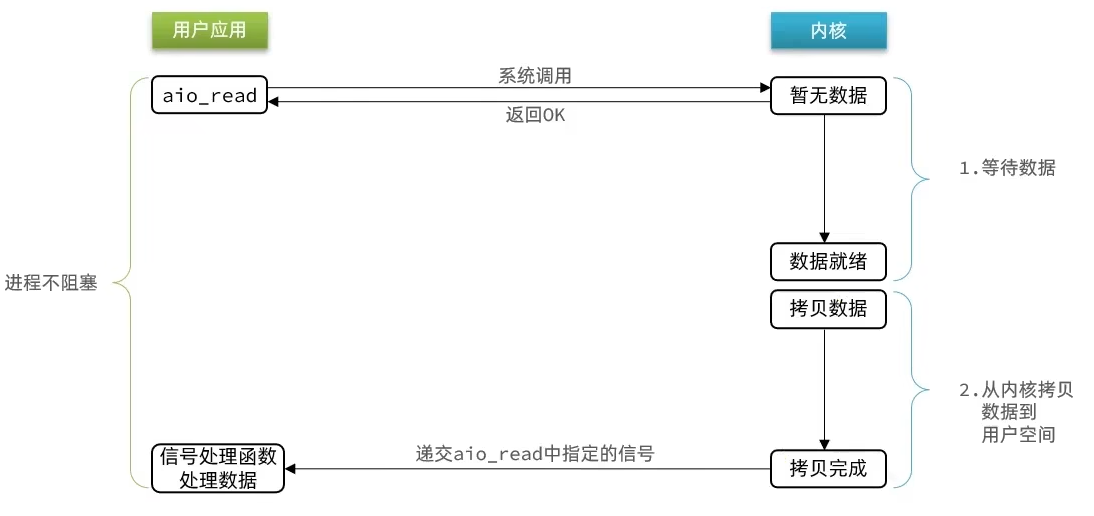
缺点:高并发下,多次调用,内核任务积累过多(内存占用过多)导致崩溃,限流控制并发