 数据类型篇
数据类型篇
# RedisObject
一个Redis节点默认有16个database,每个database维护了从key到val的映射关系,这个关系由Dict维护,Dict的key可以是string类型的,而val可以是多种数据结构,为了在同一个Dict中存储不同类型结构的val,引进了RedisObject类型;
struct redisObject {
unsigned type:4;
unsigned encoding:4;//编码
unsigned lru:LRU_BITS;
int refcount;//引用计数
void *ptr;//指向底层数据结构实例
};
2
3
4
5
6
7
# 数据结构
# SDS
struct __attribute__ ((__packed__)) hisdshdr8 {
uint8_t len; /* used */
uint8_t alloc; /* buf申请的总字节数,不包含结束标记 */
unsigned char flags; /* 不同SDS的头类型,用来控制头大小 */
//上面为Header,尾部以/0结尾
char buf[];
};
2
3
4
5
6
7
比C语言的优势:
获取字符串长度的时间复杂度为O(1)
支持动态扩容
如果新字符串小于1M,则新空间为扩展后字符串长度的两倍+1;
如果新字符串大于1M,则新空间为扩展后字符串长度+1M+1。称为内存预分配。
减少内存分配次数
SDS由于len属性和alloc属性存在,对修改字符串有内存预分配和惰性空间释放策略:
- 内存预分配:扩展的内存比实际需要的多,减少内存分配次数
- 惰性空间释放:不立即回收缩短后的多余字节,而是使用alloc属性将这些字节记录下来,等待后续使用
C语言不记录字符串长度,如果修改字符串,必须重新分配内存(先释放再申请),否则字符串长度 增加会内存缓冲区溢出,减小会内存泄露;
二进制安全
SDS以len属性表示的长度来判断字符串是否结束;
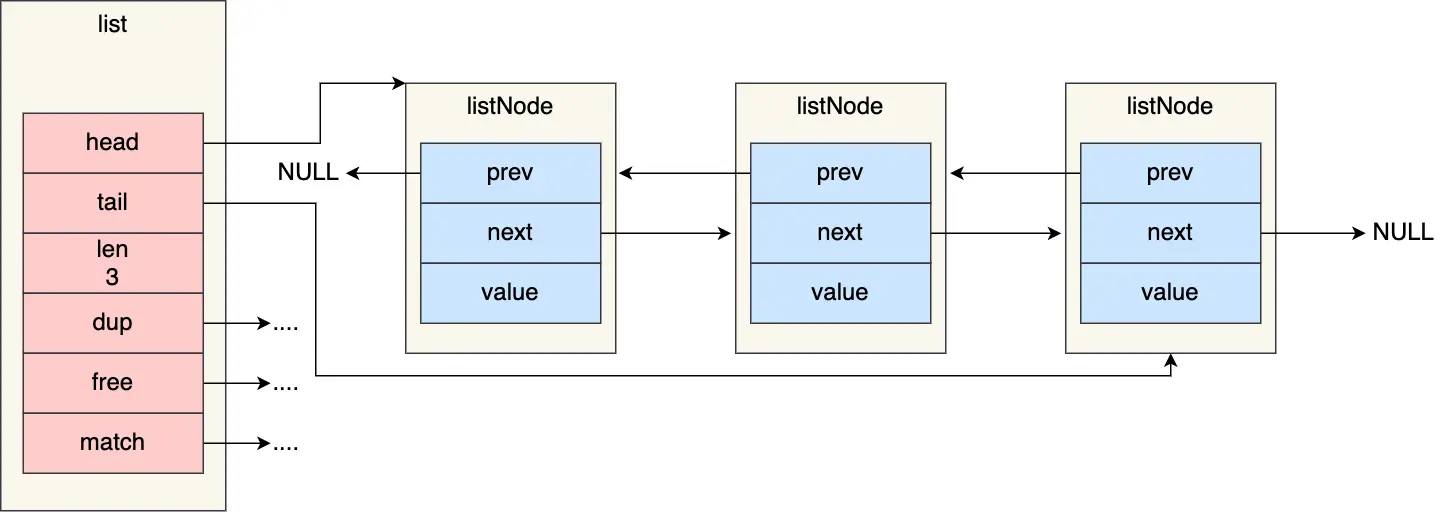
# 链表
typedef struct list {
//链表头节点
listNode *head;
//链表尾节点
listNode *tail;
//节点值复制函数
void *(*dup)(void *ptr);
//节点值释放函数
void (*free)(void *ptr);
//节点值比较函数
int (*match)(void *ptr, void *key);
//链表节点数量
unsigned long len;
} list;
2
3
4
5
6
7
8
9
10
11
12
13
14
# ZipList

压缩列表在表头有三个字段:
- zlbytes,记录整个压缩列表占用对内存字节数;
- zltail,记录压缩列表「尾部」节点距离起始地址由多少字节,也就是列表尾的偏移量;
- zllen,记录压缩列表包含的节点entry数量;
- entry,列表节点
- zlend,标记压缩列表的结束点,固定值 0xFF(十进制255)。
压缩列表节点entry包含三部分内容:
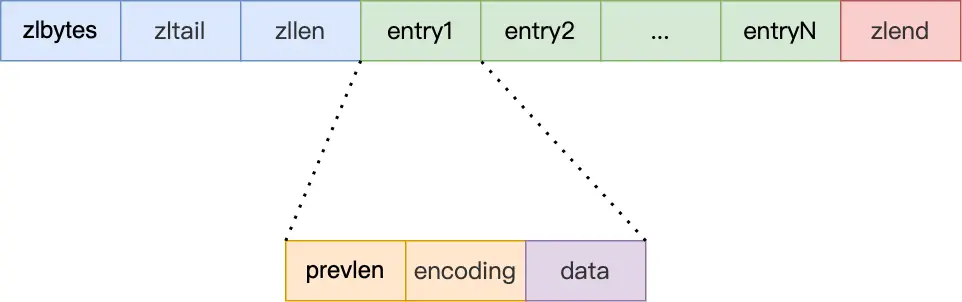
prevlen,记录了「前一个节点」的长度,目的是为了实现从后向前遍历;
压缩列表里的每个节点中的 prevlen 属性都记录了「前一个节点的长度」,而且 prevlen 属性的空间大小跟前一个节点长度值有关,比如:
- 如果前一个节点的长度小于 254 字节,那么 prevlen 属性需要用 1 字节的空间来保存这个长度值;
- 如果前一个节点的长度大于等于 254 字节,那么 prevlen 属性需要用 5 字节的空间来保存这个长度值;
encoding,记录了当前节点实际数据的「类型和长度」,类型主要有两种:字符串和整数。
- 如果当前节点的数据是整数,则 encoding 会使用 1 字节的空间进行编码,也就是 encoding 长度为 1 字节。通过 encoding 确认了整数类型,就可以确认整数数据的实际大小了,比如如果 encoding 编码确认了数据是 int16 整数,那么 data 的长度就是 int16 的大小。
- 如果当前节点的数据是字符串,根据字符串的长度大小,encoding 会使用 1 字节/2字节/5字节的空间进行编码,encoding 编码的前两个 bit 表示数据的类型,后续的其他 bit 标识字符串数据的实际长度,即 data 的长度。
data,记录了当前节点的实际数据,类型和长度都由
encoding决定;
连锁更新:
特殊情况:假设一个压缩列表中有多个连续的、长度在 250~253 之间的节点,如果再将一个长度大于等于 254 字节的新节点加入到压缩列表的表头节点,后续节点全部更新。
# quicklist
quicklist就是一个链表,每个元素是一个压缩列表;
quicklist 就是「双向链表 + 压缩列表」组合,通过控制每个链表节点中的压缩列表的大小或者元素个数,来规避连锁更新的问题。
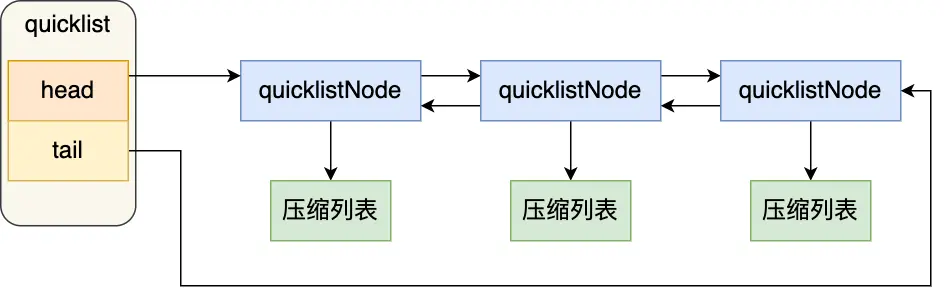
在向quicklist中添加元素时,不会直接新建一个链表节点,会检查插入位置的压缩列表是否能容纳该元素,能则直接保存quicklistNode结构里的压缩列表,不能重新建一个quicklistNode结构;
# SkipList
typedef struct zskiplist {
struct zskiplistNode *header, *tail;
unsigned long length;
int level;
} zskiplist;
2
3
4
5
Redis 只有 Zset 对象的底层实现用到了跳表,跳表的优势是能支持平均 O(logN) 复杂度的节点查找;
Zset 对象要同时保存「元素」和「元素的权重」,对应到跳表节点结构里就是 sds 类型的 ele 变量和 double 类型的 score 变量。每个跳表节点都有一个后向指针(struct zskiplistNode *backward),指向前一个节点,目的是为了方便从跳表的尾节点开始访问节点,这样倒序查找时很方便。
跳表时一个带层级关系的链表,层级关系由level数组表示,level数组中每个元素代表跳表的一层,每个元素的结构体中又定义了 指向下一个跳表节点的指针 和 跨度;
跳表查询过程会从头节点的最高层开始,逐一遍历每一层,遍历节点时会比较元素值和权重:
当前节点权重 < 查找节点的权重时,跳表会访问该层上的下一个节点;
= ,当前节点的元素值 < 要查找的元素值,跳表会访问该层上的下一个节点;
如果两个条件不满足,或下一个节点为空,跳表往下一层遍历;
typedef struct zskiplistNode {
sds ele;//Zset 对象的元素值
double score;//元素权重值
struct zskiplistNode *backward;//前一个节点指针
//节点的level数组,保存每层上的前向指针和跨度
struct zskiplistLevel {
struct zskiplistNode *forward;//后一个节点指针
unsigned long span;
} level[];//多级索引数组
} zskiplistNode;
2
3
4
5
6
7
8
9
10
跨度作用:计算这个节点在跳表中的排位;
跳表查询过程:
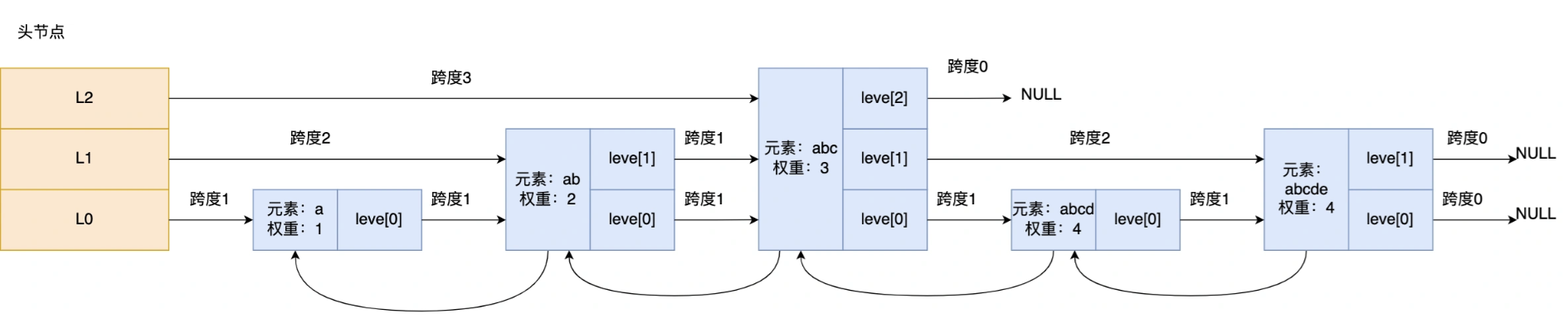
如果要查找「元素:abcd,权重:4」的节点,查找的过程是这样的:
- 先从头节点的最高层开始,L2 指向了「元素:abc,权重:3」节点,这个节点的权重比要查找节点的小,所以要访问该层上的下一个节点;
- 但是该层的下一个节点是空节点( leve[2]指向的是空节点),于是就会跳到「元素:abc,权重:3」节点的下一层去找,也就是 leve[1];
- 「元素:abc,权重:3」节点的 leve[1] 的下一个指针指向了「元素:abcde,权重:4」的节点,然后将其和要查找的节点比较。虽然「元素:abcde,权重:4」的节点的权重和要查找的权重相同,但是当前节点的 SDS 类型数据「大于」要查找的数据,所以会继续跳到「元素:abc,权重:3」节点的下一层去找,也就是 leve[0];
- 「元素:abc,权重:3」节点的 leve[0] 的下一个指针指向了「元素:abcd,权重:4」的节点,该节点正是要查找的节点,查询结束。
如何添加元素?
随机层数:50% 的概率被分配到 Level 1,25% 的概率被分配到 Level 2,12.5% 的概率被分配到 Level 3,以此类推,Redis 跳跃表默认允许最大的层数是 32;
为什么不用平衡树?
Redis是一种基于内存的数据结构。他其实不需要考虑磁盘IO的性能问题,所以,他完全可以选择一个简单的数据结构,并且性能也能接受的 ,那么跳表就很合适;
跳表相对于B+树来说,更简单。相比之下,B+树作为一种复杂的索引结构,需要考虑节点分裂和合并等复杂操作,增加了实现和维护的复杂度;
而且,Redis的有序集合经常需要进行插入、删除和更新操作。跳表在动态性能方面具有良好的表现,特别是在插入和删除操作上。相比之下,B+树的插入和删除需要考虑平衡性,所以还是成本挺高的;
# Dict
组成:字典(Dict)、哈希表(DictHashTable)、哈希节点(DictEntry)
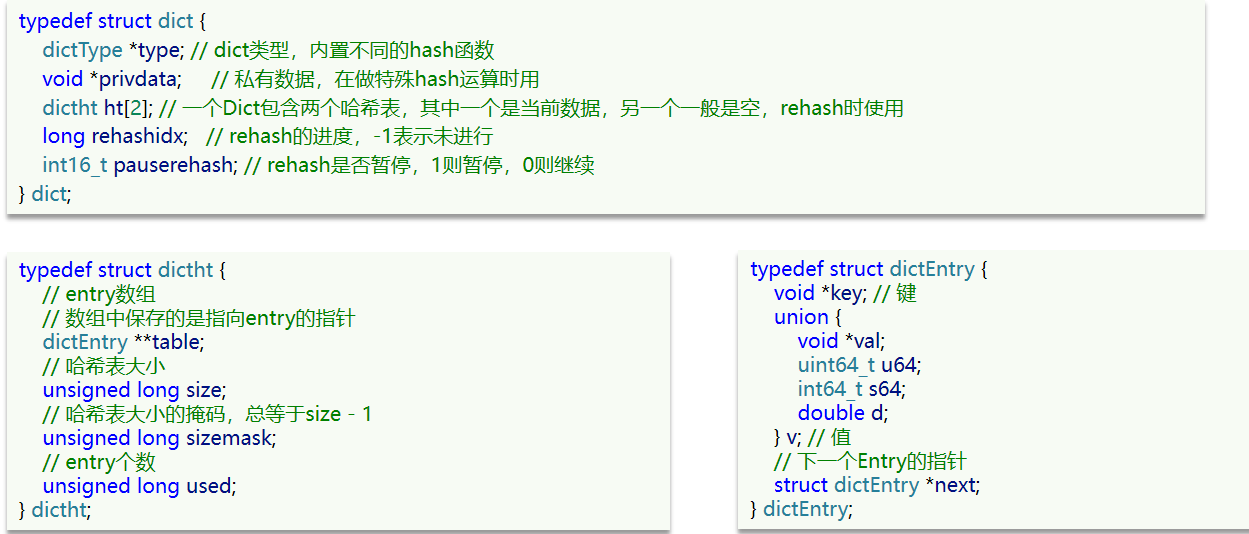

dictEntry:头插法
哈希冲突:链式哈希;
扩容时机:
- 哈希表的 LoadFactor >= 1,并且服务器没有执行 BGSAVE 或者 BGREWRITEAOF 等后台进程;
- 哈希表的 LoadFactor > 5 ;
rehash:
typedef struct dict {
…
//两个Hash表,交替使用,用于rehash操作
dictht ht[2];
…
} dict;
2
3
4
5
6
dict结构体中,定义了两个哈希表;
rehash过程:
给「哈希表 2」 分配空间,一般会比「哈希表 1」 大 2 倍;
如果是扩容,则新size为第一个大于等于dict.ht[0].used + 1的2^n
如果是收缩,则新size为第一个大于等于dict.ht[0].used的2^n (不得小于4)
将「哈希表 1 」的数据迁移到「哈希表 2」 中;
迁移完成后,「哈希表 1 」的空间会被释放,并把「哈希表 2」 设置为「哈希表 1」,然后在「哈希表 2」 新创建一个空白的哈希表,为下次 rehash 做准备。
渐进式rehash:
rehash问题:如果「哈希表 1 」的数据量非常大,那么在迁移至「哈希表 2 」的时候,因为会涉及大量的数据拷贝,此时可能会对 Redis 造成阻塞,无法服务其他请求;
- 查找一个 key 的值的话,先会在「哈希表 1」 里面进行查找,如果没找到,就会继续到哈希表 2 里面进行找到;
- 新增一个 key-value 时,会被保存到「哈希表 2 」里面,而「哈希表 1」 则不再进行任何添加操作,这样保证了「哈希表 1 」的 key-value 数量只会减少,随着 rehash 操作的完成,最终「哈希表 1 」就会变成空表;
# 数据类型
# String
字符串对象的内部编码(encoding)有 3 种 :int、raw和 embstr.
- 如果一个字符串对象保存的是整数值,并且这个整数值可以用
long类型来表示,那么字符串对象会将整数值保存在字符串对象结构的ptr属性里面(将void*转换成 long),并将字符串对象的编码设置为int - 如果字符串对象保存的是一个字符串,并且这个字符申的长度小于等于 32 字节(redis 2.+版本),那么字符串对象将使用一个简单动态字符串(SDS)来保存这个字符串,并将对象的编码设置为
embstr - 如果字符串对象保存的是一个字符串,并且这个字符串的长度大于 32 字节(redis 2.+版本),那么字符串对象将使用一个简单动态字符串(SDS)来保存这个字符串,并将对象的编码设置为
raw
embstr会通过一次内存分配函数来分配一块连续的内存空间来保存redisObject和SDS;
raw编码会通过调用两次内存分配函数来分别分配两块空间来保存redisObject和SDS;
# List
Redis3.2版本之后,List 数据类型底层数据结构就只由 quicklist 实现;
常用命令:
# 将一个或多个值value插入到key列表的表头(最左边),最后的值在最前面
LPUSH key value [value ...]
# 将一个或多个值value插入到key列表的表尾(最右边)
RPUSH key value [value ...]
# 移除并返回key列表的头元素
LPOP key
# 移除并返回key列表的尾元素
RPOP key
# 返回列表key中指定区间内的元素,区间以偏移量start和stop指定,从0开始
LRANGE key start stop
# 从key列表表头弹出一个元素,没有就阻塞timeout秒,如果timeout=0则一直阻塞
BLPOP key [key ...] timeout
# 从key列表表尾弹出一个元素,没有就阻塞timeout秒,如果timeout=0则一直阻塞
BRPOP key [key ...] timeout
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
# Hash
压缩列表或哈希表;
与String区别:
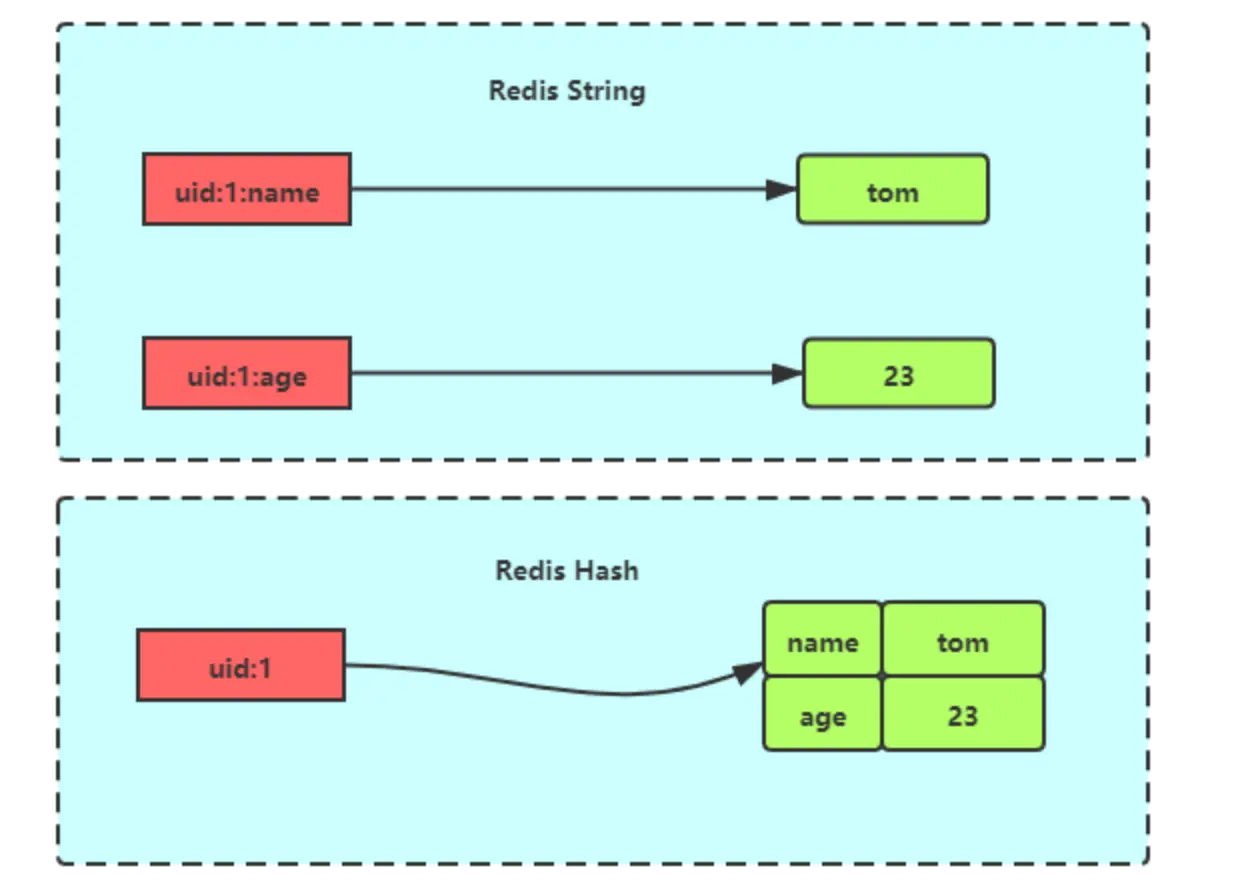
# Set
哈希表或整数集合;
与List区别:
- List可以存储重复元素,Set 只能存储非重复元素;
- List 是按照元素的先后顺序存储元素的,而 Set 则是无序方式存储元素的;
常用命令:
# 往集合key中存入元素,元素存在则忽略,若key不存在则新建
SADD key member [member ...]
# 从集合key中删除元素
SREM key member [member ...]
# 获取集合key中所有元素
SMEMBERS key
# 获取集合key中的元素个数
SCARD key
# 判断member元素是否存在于集合key中
SISMEMBER key member
# 从集合key中随机选出count个元素,元素不从key中删除
SRANDMEMBER key [count]
# 从集合key中随机选出count个元素,元素从key中删除
SPOP key [count]
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
运算操作:
# 交集运算
SINTER key [key ...]
# 将交集结果存入新集合destination中
SINTERSTORE destination key [key ...]
# 并集运算
SUNION key [key ...]
# 将并集结果存入新集合destination中
SUNIONSTORE destination key [key ...]
# 差集运算
SDIFF key [key ...]
# 将差集结果存入新集合destination中
SDIFFSTORE destination key [key ...]
2
3
4
5
6
7
8
9
10
11
12
13
14
应用场景:
点赞;
一个用户只能点一个赞,key是文章id,val是用户id;
三个用户点赞:
# uid:1 用户对文章 article:1 点赞 > SADD article:1 uid:1 (integer) 1 # uid:2 用户对文章 article:1 点赞 > SADD article:1 uid:2 (integer) 1 # uid:3 用户对文章 article:1 点赞 > SADD article:1 uid:3 (integer) 11
2
3
4
5
6
7
8
9共同关注;
key 是用户id,val是已关注的公众号id;
# uid:1 用户关注公众号 id 为 5、6、7、8、9 > SADD uid:1 5 6 7 8 9 (integer) 5 # uid:2 用户关注公众号 id 为 7、8、9、10、11 > SADD uid:2 7 8 9 10 11 (integer) 5 > SINTER uid:1 uid:2 1) "7" 2) "8" 3) "9"1
2
3
4
5
6
7
8
9
10
11
# Zset
跳表+哈希表;
Zset能支持范围查询(ZRANGEBYSCORE):跳表;
能以常数复杂度获取元素权重(ZSCORE):哈希表;
每个存储元素相当于两个值组成,一个有序集合元素值,一个排序值;

常用操作:
# 往有序集合key中加入带分值元素
ZADD key score member [[score member]...]
# 往有序集合key中删除元素
ZREM key member [member...]
# 返回有序集合key中元素member的分值
ZSCORE key member
# 返回有序集合key中元素个数
ZCARD key
# 为有序集合key中元素member的分值加上increment
ZINCRBY key increment member
# 正序获取有序集合key从start下标到stop下标的元素
ZRANGE key start stop [WITHSCORES]
# 倒序获取有序集合key从start下标到stop下标的元素
ZREVRANGE key start stop [WITHSCORES]
# 返回有序集合中指定分数区间内的成员,分数由低到高排序。
ZRANGEBYSCORE key min max [WITHSCORES] [LIMIT offset count]
# 返回指定成员区间内的成员,按字典正序排列, 分数必须相同。
ZRANGEBYLEX key min max [LIMIT offset count]
# 返回指定成员区间内的成员,按字典倒序排列, 分数必须相同
ZREVRANGEBYLEX key max min [LIMIT offset count]
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
应用场景:
排行榜
延迟队列
将任务的执行时间戳作为score,任务作为value,将任务插入到zset中;
每个任务都有一个唯一的id,任务执行时间,任务内容(如订单超时支付系统自动取消)等信息体;
另启一个线程,周期性从zset中取出score最小(最早执行的)的任务,如果该任务的score小于当前时间戳,执行该任务,否则等待一段时间再次检查,任务执行后,删除已经执行成功的任务;
项管让我用 Redis 实现延时队列,Excuse me?? - 掘金 (juejin.cn) (opens new window)
关于Redisson延迟队列的一些思考 - 掘金 (juejin.cn) (opens new window)
基于 Redisson 和 Kafka 的延迟队列设计方案 - 掘金 (juejin.cn) (opens new window)
# Stream
作为消息队列,List缺陷:
- 不能重复消费;
- 生产者子性实现全局唯一ID;
- 消费失败后,消息丢失;
Stream优势:
- 支持消息的持久化;
- 支持自动生成全局唯一ID;
- 支持ACK确认消息;
- 支持消费者组模式;
常见命令:
# XADD:插入消息,保证有序,可以自动生成全局唯一 ID;
> XADD mymq * name Nreal
"1654254953808-0"
# XLEN :查询消息长度;
# XREAD:用于读取消息,可以按 ID 读取数据;
# 从 ID 号为 1654254953807-0 的消息开始,读取后续的所有消息(示例中一共 1 条)。
> XREAD STREAMS mymq 1654254953807-0
1) 1) "mymq"
2) 1) 1) "1654254953808-0"
2) 1) "name"
2) "Nreal"
# XDEL : 根据消息 ID 删除消息;
# DEL :删除整个 Stream;
# XRANGE :读取区间消息
# XREADGROUP:按消费组形式读取消息;
# 创建一个名为 group1 的消费组,0-0 表示从第一条消息开始读取。
> XGROUP CREATE mymq group1 0-0
OK
# XPENDING 和 XACK:
# XPENDING 命令可以用来查询每个消费组内所有消费者「已读取、但尚未确认」的消息;
# XACK 命令用于向消息队列确认消息处理已完成;
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
作为消息队列特征:
消息有序;
消息不重;
Stream在使用XADD命令,自动生成全局唯一ID;
消息可靠性;
内部使用 PENDING List 自动保存消息,使用 XPENDING 命令查看消费组已经读取但是未被确认的消息,消费者使用 XACK 确认消息;
消息不丢;
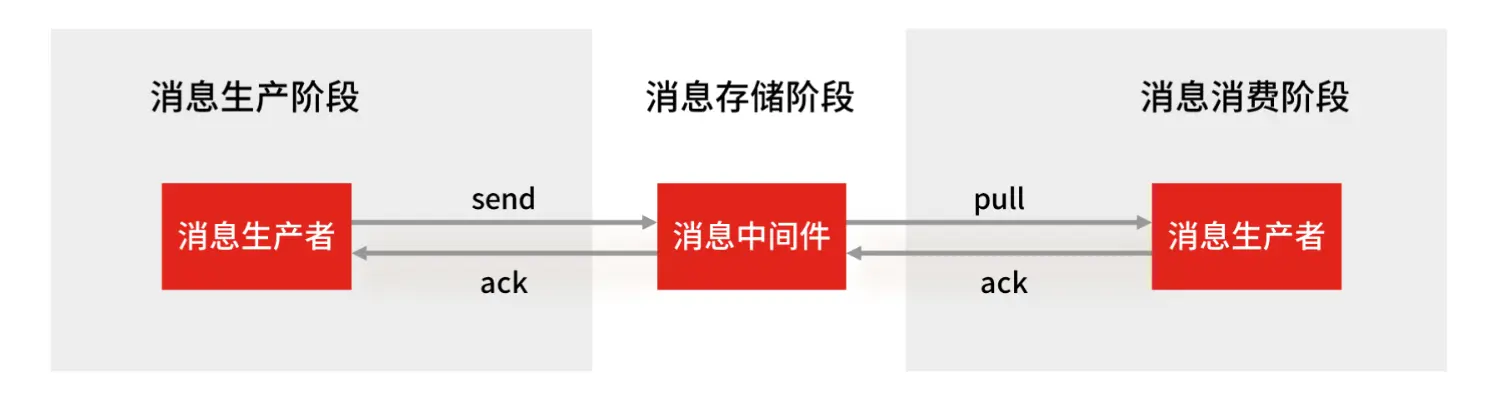
生产者—中间件:生产者收到中间件的ACK确认,表示发送成功;
中间件—消费者:PENDING List保存消费者组未被确认的消息,消费者重启后用 XPENDING 命令查看已读取、但尚未确认处理完成的消息。等到消费者执行完业务逻辑后,再发送消费确认 XACK 命令,也能保证消息的不丢失;
中间件:会丢失
- AOF 持久化配置为每秒写盘,但这个写盘过程是异步的,Redis 宕机时会存在数据丢失的可能;
- 主从复制也是异步的,主从切换时,也存在丢失数据的可能;
可堆积;
Stream 在消息积压时,如果指定了最大长度,有可能丢失消息的;