 基础篇
基础篇
# 何为关系型数据库?
一种建立在关系模型上的数据库,关系模型表明了数据库中所存储的数据之间的联系(一对一、一对多、多对多);
数据库表中的每行数据都存放着一条数据,可以使用 sql 来操作数据,并且支持 ACID 四大事务特性;
# Mysql特性
跨平台;
高性能;
性能优化:索引,查询优化,缓存等;
可扩展;
主从,分区;
安全性
用户认证、权限管理、SSL加密等;
# DDL
数据库操作:
-- 查询所有数据库:
SHOW DATABASES;
-- 查询当前数据库:
SELECT DATABASE();
-- 创建数据库:
CREATE DATABASE [ IF NOT EXISTS ] 数据库名 [ DEFAULT CHARSET 字符集] [COLLATE 排序规则 ];
-- 删除数据库:
DROP DATABASE [ IF EXISTS ] 数据库名;
-- 使用数据库:
USE 数据库名;
1
2
3
4
5
6
7
8
9
10
2
3
4
5
6
7
8
9
10
UTF8字符集长度为3字节,有些符号占4字节,所以推荐用utf8mb4字符集
表操作:
-- 查询当前数据库所有表:
SHOW TABLES;
-- 查询表结构:
DESC 表名;
-- 查询指定表的建表语句:
SHOW CREATE TABLE 表名;
-- 创建表:
CREATE TABLE 表名(
字段1 字段1类型 [COMMENT 字段1注释],
...
字段n 字段n类型 [COMMENT 字段n注释]
)[COMMENT 表注释];
-- 添加字段:
ALTER TABLE 表名 ADD 字段名 类型(长度) [COMMENT 注释] [约束];
-- 修改数据类型:
ALTER TABLE 表名 MODIFY 字段名 新数据类型(长度);
-- 修改字段名和字段类型:
ALTER TABLE 表名 CHANGE 旧字段名 新字段名 类型(长度) [COMMENT 注释] [约束];
-- 删除字段:
ALTER TABLE 表名 DROP 字段名;
-- 修改表名:
ALTER TABLE 表名 RENAME TO 新表名
-- 删除表:
DROP TABLE [IF EXISTS] 表名;
-- 清空表:
TRUNCATE TABLE 表名;
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
# DML
-- 指定字段:
INSERT INTO 表名 (字段名1, 字段名2, ...) VALUES (值1, 值2, ...);
-- 全部字段:
INSERT INTO 表名 VALUES (值1, 值2, ...);
-- 批量添加数据:
INSERT INTO 表名 (字段名1, 字段名2, ...) VALUES (值1, 值2, ...), (值1, 值2, ...);
INSERT INTO 表名 VALUES (值1, 值2, ...), (值1, 值2, ...);
-- 修改数据:
UPDATE 表名 SET 字段名1 = 值1,字段名2 = 值2, ... [WHERE 条件];
-- 删除数据:
DELETE FROM 表名 [ WHERE 条件];
1
2
3
4
5
6
7
8
9
10
11
2
3
4
5
6
7
8
9
10
11
# DQL
SELECT
字段列表
FROM
表名字段
WHERE
条件列表
GROUP BY
分组字段列表
HAVING
分组后的条件列表
ORDER BY
排序字段列表
LIMIT
分页参数
1
2
3
4
5
6
7
8
9
10
11
12
13
14
2
3
4
5
6
7
8
9
10
11
12
13
14
聚合函数:count,max,min,avg,sum...
分组查询:
SELECT 字段列表 FROM 表名 [ WHERE 条件 ] GROUP BY 分组字段名 [ HAVING 分组后的过滤条件 ];
1
开发中,我们使用HAVING的前提是SQL中使用了GROUP BY。
where 和 having 的区别:
- 执行时机不同:where是分组之前进行过滤,不满足where条件不参与分组;having是分组后对结果进行过滤。
- 判断条件不同:where不能对聚合函数进行判断,而having可以。
注意事项:
- 执行顺序:where > 聚合函数 > having
- 分组之后,查询的字段一般为聚合函数和分组字段,查询其他字段无任何意义
执行顺序:
FROM -> WHERE -> GROUP BY -> SELECT -> ORDER BY -> LIMIT
# CRUD
# 插入数据
插入完整行
# 插入一行 INSERT INTO user VALUES (10, 'root', 'root', 'xxxx@163.com'); # 插入多行 INSERT INTO user VALUES (10, 'root', 'root', 'xxxx@163.com'), (12, 'user1', 'user1', 'xxxx@163.com'), (18, 'user2', 'user2', 'xxxx@163.com');1
2
3
4
5
6插入行中一部分
INSERT INTO user(username, password, email) VALUES ('admin', 'admin', 'xxxx@163.com');1
2插入查询出的数据
INSERT INTO user(username) SELECT name FROM account;1
2
3
# 更新数据
UPDATE user
SET username='robot', password='robot'
WHERE username = 'root';
1
2
3
2
3
# 删除数据
DELETE删除表中记录
DELETE FROM user WHERE username = 'robot';1
2TRUNCATE清空表,删除所有行
TRUNCATE TABLE user;1
# 查询数据
查询不同的值
SELECT DISTINCT vend_id FROM products;1
2限制查询结果
-- 返回前 5 行 SELECT * FROM mytable LIMIT 5; SELECT * FROM mytable LIMIT 0, 5; -- 返回第 3 ~ 5 行 SELECT * FROM mytable LIMIT 2, 3;1
2
3
4
5
# 分组
group by 为每个组返回一个记录,可以涉及聚合
count,max,sum,avg等;
分组后排序:
SELECT cust_name, COUNT(cust_address) AS addr_num
FROM Customers GROUP BY cust_name
ORDER BY cust_name DESC;
1
2
3
2
3
having vs where
where:过滤过滤指定的行,后面不能加聚合函数(分组函数)。where在group by前。having:过滤分组,一般都是和group by连用,不能单独使用。having在group by之后。
SELECT cust_name, COUNT(*) AS num
FROM Customers
WHERE cust_email IS NOT NULL
GROUP BY cust_name
HAVING COUNT(*) >= 1;
1
2
3
4
5
2
3
4
5
# DCL
-- 查询用户:
USE mysql;
SELECT * FROM user;
-- 创建用户:
CREATE USER '用户名'@'主机名' IDENTIFIED BY '密码';
-- 修改用户密码:
ALTER USER '用户名'@'主机名' IDENTIFIED WITH mysql_native_password BY '新密码';
-- 删除用户:
DROP USER '用户名'@'主机名';
-- 查询权限:
SHOW GRANTS FOR '用户名'@'主机名';
-- 授予权限:
GRANT 权限列表 ON 数据库名.表名 TO '用户名'@'主机名';
-- 撤销权限:
REVOKE 权限列表 ON 数据库名.表名 FROM '用户名'@'主机名';
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
2
3
4
5
6
7
8
9
10
11
12
13
14
15
# 约束
常用约束:
| 约束条件 | 关键字 |
|---|---|
| 主键 | PRIMARY KEY |
| 自动增长 | AUTO_INCREMENT |
| 不为空 | NOT NULL |
| 唯一 | UNIQUE |
| 逻辑条件 | CHECK |
| 默认值 | DEFAULT |
create table user(
id int primary key auto_increment,
name varchar(10) not null unique,
age int check(age > 0 and age < 120),
status char(1) default '1',
gender char(1)
);
1
2
3
4
5
6
7
2
3
4
5
6
7
外键约束:
外键用来让两张表的数据之间建立连接,从而保证数据的一致性和完整性
-- 添加外键
CREATE TABLE 表名(
字段名 字段类型,
...
[CONSTRAINT] [外键名称] FOREIGN KEY(外键字段名) REFERENCES 主表(主表列名)
);
ALTER TABLE 表名 ADD CONSTRAINT 外键名称 FOREIGN KEY (外键字段名) REFERENCES 主表(主表列名);
-- 例子
alter table emp add constraint fk_emp_dept_id foreign key(dept_id) references dept(id);
-- 删除外键
ALTER TABLE 表名 DROP FOREIGN KEY 外键名;
1
2
3
4
5
6
7
8
9
10
11
12
13
2
3
4
5
6
7
8
9
10
11
12
13
外键缺陷:
- 级联问题:每次级联delete或update的时候,都要级联操作相关的外键表,不论有没有这个必要,由其在高并发的场景下,这会导致性能瓶颈;
- 增加数据库压力:外键等于把数据的一致性事务实现,全部交给数据库服务器完成,并且有了外键,当做一些涉及外键字段的增,删,更新操作之后,需要触发相关操作去检查,而不得不消耗资源;
- 死锁问题:高并发大流量事务场景,使用外键还可能容易造成死锁;
# 多表查询
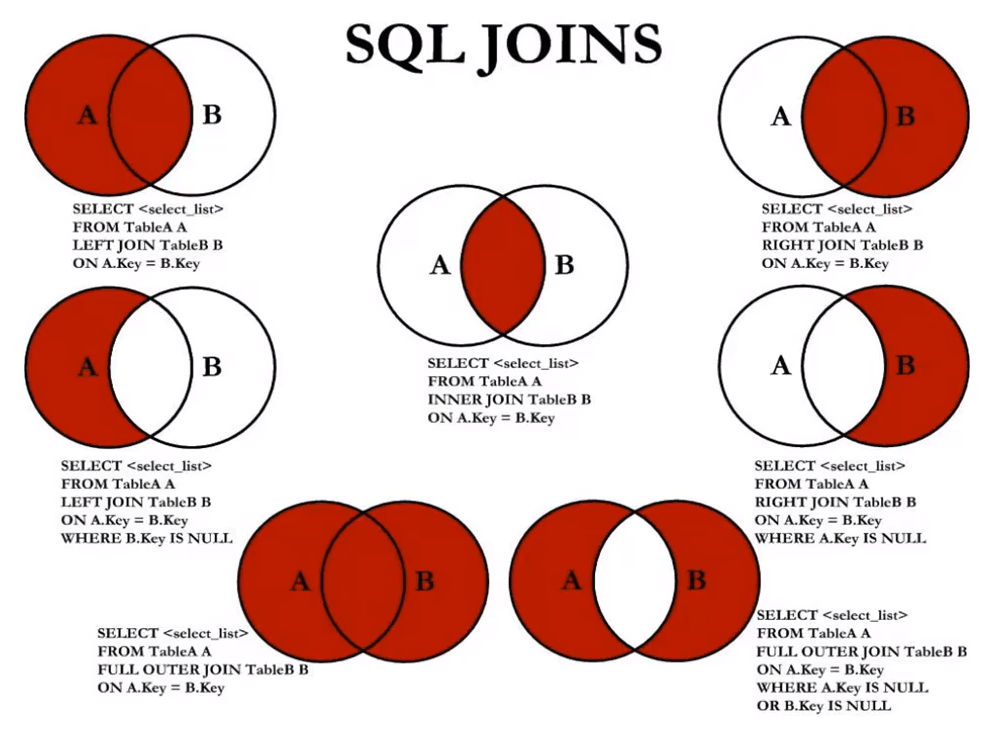
如果两张表的关联字段名相同,也可以使用 USING子句来代替 ON:
# join....on
select c.cust_name, o.order_num
from Customers c
inner join Orders o
on c.cust_id = o.cust_id
order by c.cust_name;
# 如果两张表的关联字段名相同,也可以使用USING子句:join....using()
select c.cust_name, o.order_num
from Customers c
inner join Orders o
using(cust_id)
order by c.cust_name;
1
2
3
4
5
6
7
8
9
10
11
12
13
2
3
4
5
6
7
8
9
10
11
12
13
# 函数
# 文本处理
| 函数 | 说明 |
|---|---|
LEFT()、RIGHT() | 左边或者右边的字符 |
LOWER()、UPPER() | 转换为小写或者大写 |
LTRIM()、RTRIM() | 去除左边或者右边的空格 |
LENGTH() | 长度,以字节为单位 |
SOUNDEX() | 转换为语音值 |
# 日期和时间处理
- 日期格式:
YYYY-MM-DD - 时间格式:
HH:MM:SS
| 函 数 | 说 明 |
|---|---|
AddDate() | 增加一个日期(天、周等) |
AddTime() | 增加一个时间(时、分等) |
CurDate() | 返回当前日期 |
CurTime() | 返回当前时间 |
Date() | 返回日期时间的日期部分 |
DateDiff() | 计算两个日期之差 |
Date_Add() | 高度灵活的日期运算函数 |
Date_Format() | 返回一个格式化的日期或时间串 |
Day() | 返回一个日期的天数部分 |
DayOfWeek() | 对于一个日期,返回对应的星期几 |
Hour() | 返回一个时间的小时部分 |
Minute() | 返回一个时间的分钟部分 |
Month() | 返回一个日期的月份部分 |
Now() | 返回当前日期和时间 |
Second() | 返回一个时间的秒部分 |
Time() | 返回一个日期时间的时间部分 |
Year() | 返回一个日期的年份部分 |
# 数据库三大范式
- 数据库表每一列都是不可分割的原子数据项;
- 数据库表每一列都和主键相关;
- 每一列数据都和主键直接相关,而不能间接相关;