 持久化篇
持久化篇
# RDB
全量快照,把某一时刻的数据以文件的形式拍下来,写到磁盘上;
RDB文件内容是二进制数据;
# 触发时机
执行save命令
在主线程生成 RDB 文件,由于和执行操作命令在同一个线程,所以如果写入 RDB 文件的时间太长,会阻塞主线程;
执行bgsave命令
持久化时,fork一个子进程,全权负责持久化工作,这样主进程仍可以给客户端提供服务,子进程读取这个副本数据写到 RDB 文件;
fork采用的是copy-on-write写时复制技术:
- 当主进程执行读操作时,子进程与父进程共享一段物理内存;
- 当主进程执行写操作时,则会拷贝一份数据,给主进程去修改。

在执行 SAVE 或 BGSAVE 命令创建一个新的 RDB 文件时,程序会对数据库中的键进行检查,已过期的键不会被保存到新创建的RDB 文件中。这既保证了快照的完整性,也允许主线程同时对数据进行修改,避免了对正常业务的影响;
执行快照时,数据能被修改吗?
答:能,bgsave快照过程中,如果主线程修改了共享数据,发生了写时复制后,RDB 快照保存的是原本的内存数据,而主线程刚修改的数据,是没办法在这一时间写入 RDB 文件的,只能交由下一次的 bgsave 快照;
# 优点
- RDB 文件是一个很简洁的单文件,采用 二进制 + 数据压缩 的方式写磁盘,文件体积小,数据恢复速度快。
- RDB 的性能很好,需要进行持久化时,主进程会 fork 一个子进程出来,然后把持久化的工作交给子进程,自己不会有相关的I/O操作。
# 缺陷
RDB执行快照是一个比较重的操作,如果频率太频繁,可能会对 Redis 性能产生影响。如果频率太低,服务器故障时,丢失的数据会更多(而 AOF 日志可以以秒级的方式记录操作命令,所以丢失的数据就相对更少);
bgsave命令在fork子进程、压缩、写出RDB文件都比较耗时;
# AOF
AOF持久化将修改数据库状态的命令保存到AOF文件中;
记录的是命令;RDB记录的是数据,恢复大量数据的时候,RDB更快;
开启AOF:redis.conf
# 是否开启AOF功能,默认是no appendonly yes # AOF文件的名称 appendfilename "appendonly.aof"1
2
3
4
# 比RDB的优势?
安全性更好,生成RDB文件过程更繁重,虽然bgsave不会阻塞主线程,但是也会影响CPU资源和内存资源;
AOF支持秒级的数据丢失(写回策略设置为everysec);
不建议单独使用AOF,可以同时开启RDB和AOF持久化;
# 写回策略
Redis是先执行写操作命令后,再将该命令记录到AOF日志中;
为什么不 WAL?
答:像mysql中redolog 记录的是数据,AOF记录的是命令;
好处:
- 避免额外检查开销:如果当前的命令语法有问题,那么如果不进行命令语法检查,该错误的命令记录到 AOF 日志里后,Redis 在使用日志恢复数据时,就可能会出错;
风险:
- 数据丢失风险:先写日志,宕机,还没来得及写磁盘;
- 给下条命令带来阻塞风险:写操作命令执行成功后才记录到 AOF 日志,所以不会阻塞当前写操作命令的执行(执行命令与写日志操作都是主进程完成的,同步操作),如果将日志内容写入到硬盘时,服务器的硬盘的 I/O 压力太大,就会导致写硬盘的速度很慢,进而阻塞住了,也就会导致后续的命令无法执行;
这两个风险都和AOF写回磁盘的时机相关,空值每个命令执行后AOF日志写回磁盘就可以解决;
Redis写入AOF日志过程:
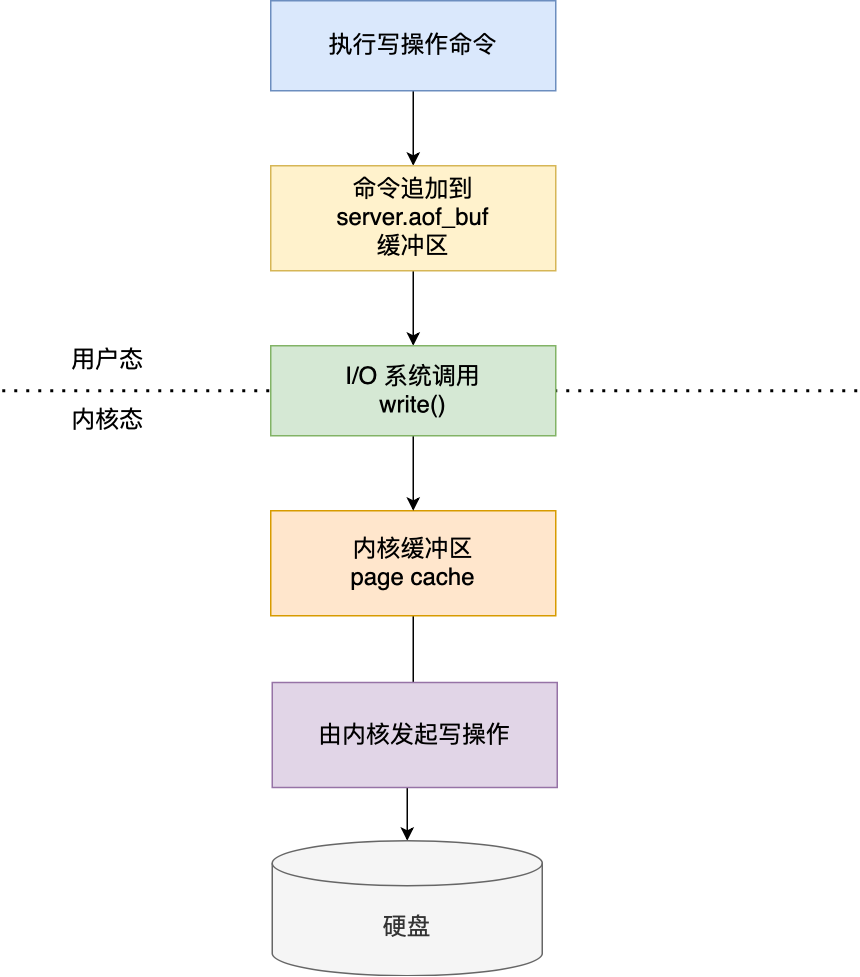
Redis 执行完写操作命令后,会将命令追加到
server.aof_buf缓冲区;然后通过 write() 系统调用,将 aof_buf 缓冲区的数据写入到 AOF 文件,此时数据并没有写入到硬盘,而是拷贝到了内核缓冲区 page cache,等待内核将数据写入硬盘;
具体内核缓冲区的数据什么时候写入到硬盘,由内核决定。
在
redis.conf配置文件中的appendfsync配置项可以有以下 3 种参数可填:- Always:每次写操作命令执行完,同步将AOF日志数据写回磁盘,能保证数据不丢失,但是影响主进程性能;
- No:先将命令写入到 AOF 文件的内核缓冲区,再由操作系统决定何时将缓冲区内容写回磁盘,不由Redis控制,性能好,但是服务器宕机会丢失数据;
- Everysec:每次写操作命令执行完后,先将命令写入到 AOF 文件的内核缓冲区,然后每隔一秒将缓冲区里的内容写回到磁盘;
底层实现:fsync()函数调用时机
- Always 策略就是每次写入 AOF 文件数据后,就执行 fsync() 函数;
- Everysec 策略就会创建一个异步任务来执行 fsync() 函数;
- No 策略就是永不执行 fsync() 函数;
# 重写机制
AOF记录的时一个个指令,会导致保存的文件太大,故障恢复时如果日志文件太大,整个恢复过程非常慢;
Redis为了避免AOF文件越写越大,当 AOF 文件的大小超过所设定的阈值后,Redis 就会启用 AOF 重写机制,来压缩 AOF 文件;
重写时,读取当前数据库的所有键值对,然后将每一个键值对用一条命令记录到 新的AOF文件 中,记录完成后,将新的 AOF 文件替换现有的 AOF 文件;
总结:重写机制目的就是针对被反复修改某些键值对,只需要记录它的最终状态;而重写时需要用新的AOF文件覆盖现有的AOF文件,是为了防止重写过程失败,现有的AOF文件收到污染;
AOF后台重写:
不会阻塞主线程;
fork重写子进程,如果主进程修改了已存在的 k-v,就触发写时复制,只会复制主进程修改的物理内存数据,没修改的物理内存还是与子进程共享的;
如果主进程又修改了数据,如何解决主进程与子进程数据不一致?
答:
重写缓冲区,当Redis执行完一条命令后,同时将这个命令写入到AOF缓冲区和AOF重写缓冲区;
当子进程完成 AOF 重写工作(扫描数据库中所有数据,逐一把内存数据的键值对转换成一条命令,再将命令记录到重写日志)后,向主进程发送信号,主进程收到信号后,调用一个信号处理函数,将 AOF 重写缓冲区中的所有内容追加到新的 AOF 的文件中,覆盖现有AOF文件;
# BigKey对持久化影响
- AOF写回策略配置为Always,如果为大key,主线程执行fsync()函数时,阻塞的时间比较久;
- AOF重写机制与RDB的bgsave命令,若触发写时复制,会拷贝物理内存,大key的物理内存占用很大,在复制阶段会阻塞父进程;
其它影响:
- 网络阻塞:对 BigKey 执行读请求时,少量的QPS就可能导致带宽使用率被占满,导致Redis实例,乃至所在物理机变慢;
- 数据倾斜:集群模型在 slot 分片均匀情况下,会出现数据和查询倾斜情况,部分有大 key 的 Redis 节点占用内存多,QPS 也会比较大;
查找大key:
redis-cli -a 密码 --bigkeys异步删除大key:
unlink大Key的优化方案:
对大key进行拆分;
对大key进行清理;
采用unlink命令安全删除,或通过定时任务方式对失效数据定期清理;
问:假如有hash类型的key,其中有100万对field和value,field是自增id,这个key存在什么问题?如何优化?
key field value someKey id:0 value0 ..... ..... id:999999 value999999 存在的问题:hash的 entry数量超过500时,会使用哈希表而不是ZipList,内存占用较多;可以通过hash-max-ziplist-entries配置entry上限。但是如果entry过多就会导致BigKey问题;
解决:拆分为小的hash,将 id / 100 作为key, 将id % 100 作为field,这样每100个元素为一个Hash
key field value key:0 id:00 value0 ..... ..... id:99 value99 key:1 id:00 value100 ..... ..... id:99 value199 .... key:9999 id:00 value999900 ..... ..... id:99 value999999
# RDB与AOF使用场景
RDB:宕机快速恢复;
AOF:写后日志,避免宕机数据丢失;
# 写前日志和写后日志对比?
- 写前日志(WAL):实际写数据前,将修改的数据写到日志文件中,故障恢复得以保证,如MySQL Innodb 存储引擎中的 redo log(重做日志)便是记录修改的数据日志,在实际修改数据前先记录修改日志再执行修改数据;
- 写后日志:先执行“写”指令请求,将数据写入内存,再记录日志;
写后日志好处?
避免额外检查开销,不需要对执行的命令进行语法检查。如果使用写前日志的话,就需要先检查语法是否有误,否则日志记录了错误的命令,在使用日志恢复的时候就会报错。另外,写后记录日志,避免了阻塞当前“写”指令的执行。